1.データベースの更新のタイミングについて
データベースの更新のタイミングは使用する環境によって考えなければなりません。

企業でオフィスコンピュータを使用していた時代は、決まった画面で決まった操作をしていました。そのため業務は「データベース」に直結していた時代と言えます。
今日、WindowsやMacOSなどGUI操作が普及し、一つの端末でいろいろなアプリケーションを動かしたり、オンライン処理を行うことができるようになったため、「データベース」というものが難しく感じられるようになったわけです。これはオフィスコンピュータの時代とは違い、現在は「クリック」ひとつでアプリケーションを簡単に動かせるため、「データの処理の方法」というのが感覚的に分からなくなってきたからだと思います。
「データベース」は個人のパソコンとは違い、「データを共有」するために作られたものです。
「データ共有」とはその名の通り、「みんなでデータを使用する」ことです。そのため、データベースの内容はデータ共有を行なうにあたり、すべての使用する人が同じデータを使用しなければなりません。
この事は一見当たり前で簡単そうに思えますが、実はデータベース設計を行うに当たっては非常に難しいことになります。
どういうことかと言いますと、データベースの内容は常に使用され追加・更新・削除などが行われていますが、使用する用途により追加・更新・削除を行うタイミングが違い、使い分けなければなりません。
例えば、使用する人がすべて同じデータを使用しなければならないのか、または常に最新のデータを使用しなければならないのかによっても違ってきます。
これらの使用用途などによってデータベースやアプリケーションなどの基本設計や設計思想を組み立てることを「アーキテクチャ」と言います。ではどんなタイミングでデータベースを更新していくか説明していきたいと思います。
2.バッチ処理について
一括処理の方法は少々難しい処理です。

データを一括で更新を行うことを「バッチ処理」と言います。それに対し、即時に更新を行う方法を「リアルタイム処理」といいます。情報認定試験などではここまでの説明でしか行われておりません。
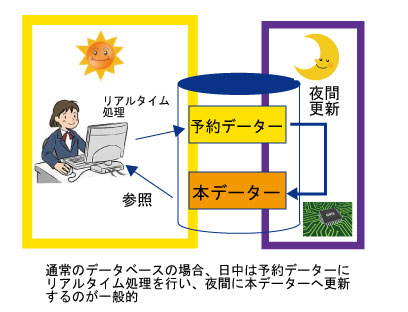
通常のデータベース操作の場合、即時に反映させる場面が多く「リアルタイム処理」となっていますが、実は「リアルタイム処理」を行っているのは一時ファイルや予約ファイルなどで、実際にはある一定の更新処理で予約ファイルから実ファイルへ更新する「バッチ処理」を行っているケースがよくあります。
 ▲データベース更新例
▲データベース更新例
なぜ、このような方法を行っているかというと、大事なデータの場合、直接実ファイルを更新すると、更新後は元に戻せなくなります。管理情報が入っているいわゆる「マスターデータ」の場合、間違ったデータを入力した場合元に戻せません。そのため、大事なデータを更新しない限りは元に戻せるようにするのが一般となります。
このバッチ処理はデータベースの更新においては重要な役割となります。実はこの「バッチ処理」は単純な処理方法でありながら非常に難しい所があります。この「バッチ処理」についてもう少し掘り下げて説明していきたいと思います。
1.バッチ処理の長所と短所
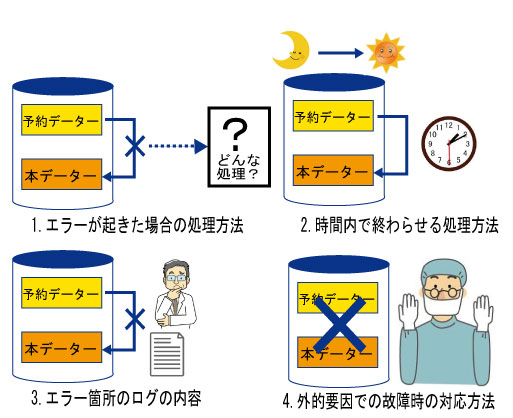
バッチ処理は更新を一括して行うため、ユーザーの操作なく時間や処理方法で更新を行うことができます。しかし、使用する環境はまちまちで、環境によって起こりうる問題を設計段階で考慮しなければなりません。それは次のことが考えられます。
 ▲バッチ処理の設計時の問題考慮
▲バッチ処理の設計時の問題考慮
1. 大量のデータを一括して処理するため、エラーになった場合にどんな処理を行うか。
2. スケジュールで処理を行う場合、大量データの更新処理を時間内で終わらせなければならない。
3. 監視が行えないので、エラーや処理状況などの「ログ」を取る必要がある。そのログはどんな「ログ」が必要になるか。
4. 外的要因やデータ内による障害が発生する可能性があるため、障害が起きた場合の対処方法を考えなければならない。
これ以外にもさまざまなことが考えられますが、特に上記の項目の事はバッチ処理を行う上で非常に重要な要素となります。
これらの要素をいかにクリアすることができるのか、次に実際に使用する環境を想定しながら考えてみましょう。
1.どんな環境で処理を行うか
一言で「データ更新」といってもさまざまな方法があります。ファイル単位で処理するのかまたはレコード単位で処理するのかによって違ってきます。処理の方法を分類すると次のようになります。
 ▲データベースの更新方法
▲データベースの更新方法
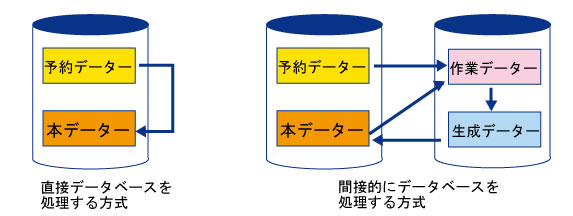
1.直接データベースを処理(参照・更新等)する
この方法の場合、直接データベースを更新するので、処理速度は高速になります。また、直接データを書き込むため、最小限のデータの転送しか発生しません。反面、データベースとプログラム間のアクセス頻度が多くなるため、データベースに負担がかかります。また、障害が起きた場合直接データベースを更新しているため、どこのデータが破損しているかなどのメンテナンスが難しくなります。
2.間接的にデータベースを処理(参照・更新等)する
この方法は一旦必要なデータベースのデータを別のデータベースなどに書き込み、その別データベース上で更新や処理を行い、全部の処理が終了後、元のデータベースに書き込む方法です。
この方法は直接データベースを処理する方法とは違い、処理の速度が低下します。しかし、直接元のデータベースとのアクセス数が少なくなるため、データベースに対する負荷を分散することが出来ます。
また、障害発生時は元のデータベースはそのままであり、処理している別のデータベースには処理に必要なデータしか書き込んでいませんので、データの破損や普及などのメンテナンスが容易に行えます。
データベース処理を行う場合、一番重要なのが障害発生時の普及の容易さにあります。
データの量にもよりますが、単純なデータ更新(同じ項目が既にあり、単純にそのデータに上書きするなど)の場合は直接データベースを処理する方が向いています。しかし、AデータとBデータを統合しデータを作るなど複雑な処理の場合は間接的にデータベースを処理させる方法が良く、障害発生のリスクも少なくなります。
2.処理するタイミングはどのタイミングか
次に考慮しなければならないのが処理を行うタイミングです。処理するタイミングは随時方式と常駐方式の2種類があります。
随時方式は必要な時に都度起動して処理を行う方式で、日時処理や月次処理、時間での起動などスケジュールで実行を行う方式や、必要に応じて手動で起動させる方式です。
この方式の特徴はデータをまとめて処理を行うため、複雑な処理などを行う場合、業務に支障をきたすことなく処理を行うことができます。
この方式を行う場合「排他制御」が必要になります。「排他制御」とは処理を実行する場合、データベースなど複数のプロセス(処理)からの同時アクセスにより競合が発生する場合に、優先順位の高い処理に独占的に占有させるため、他のプロセスが利用できないようにすることを言います。
随時処理で処理を行っている場合、処理中に他のプロセスでデータを更新してしまうと、データの整合性が取れなくなります。そのため「排他制御」が必要になります。
「排他制御」にも2つの方法があります。
1. ペシミスティック(Pessimistic・悲観的)排他制御
2. オプティミスティック(Optimistic・楽観的)排他制御
です。
 ▲ベシミスティック排他制御とオプティミスティック排他制御
▲ベシミスティック排他制御とオプティミスティック排他制御
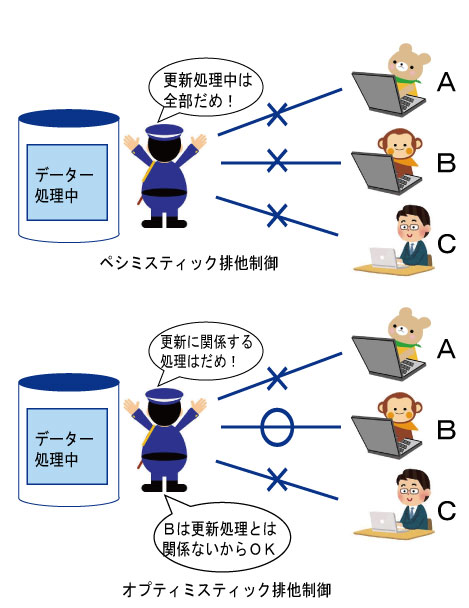
ペシミスティック排他制御は処理をする場合、最初から最後まで排他制御をかける方式です。
この方法は最初から最後まで排他制御を行うため、処理を行う場合、データベースを独占することが出来ます。一方、排他制御でデータベースを占有するため、他のプロセスが使用できなくなり、全体のパフォーマンスが低下します。
オプティミスティック排他制御はデータを更新する直前に他のプロセスの排他を確認し、排他制御を行う方式です。この方式はペシミスティック排他制御とは違い、更新する直前で排他制御を行うため、最小限の時間でデータベースを独占することになり、他のプロセスが使用できる時間が出来ます。
反面、処理している時間に他のプロセスがデータを書き換えてしまう危険性もあり、データの信頼性が問題にあり、場合によってはデータの衝突が起きる可能性もあります。
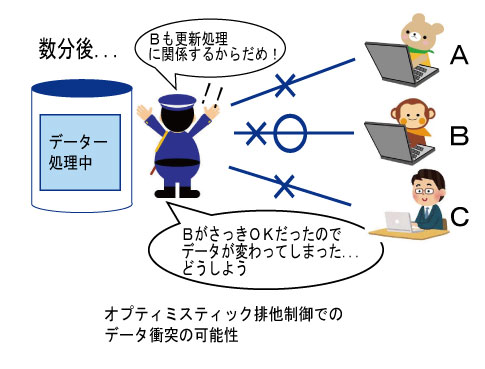 ▲オプティミスティック排他制御でのデータ衝突の可能性
▲オプティミスティック排他制御でのデータ衝突の可能性
このように随時方式はデータベースの占有時間や処理方法が大きなカギとなります。しかし、大きな処理を行う場合はこの方法をとるのが一般的です。
常駐方式は
バッチ処理プロセスを常駐させて監視する方式です。この方式は一定時間(分単位)の間隔ごとに処理を行ったり、即時バッチを起動させる場合などに使用します。
例えば、オンライン上での要求に対し、更新完了などの確認のメッセージを返したり、マスターなどのデータの即時更新が必要な場合などに使用します。
この方式は常にバッチが起動状態にあるため、マシンのメモリ消費やリソース消費などの問題もありますが、頻度に更新を行う処理の場合、いちいち起動処理を行わなくても処理できる方法です。
一方この処理の場合、データの衝突などに気をつけなければなりません。同じデータを同時に処理した場合、データの衝突などが起こります。そのため、常駐方式を行うにはデータの受信などのフォルダを一つにし、随時処理で説明したオプティミスティック排他制御をうまく使用しなければなりません。
3.処理する時間を短くするには
バッチ処理を行う場合、処理の時間の問題が発生します。
常駐方式で処理を行う場合は特に問題はありませんが、随時処理で処理を行う場合、第1節で説明した直接データベースを処理のか、間接的にデータベースを更新するのかで大きく変わってきます。
処理を実行する場合、対象となるデータの量や処理の過程の複雑さによって全体の処理の時間が決まってきますが、スケジュールなどで処理を実行する場合は決められた時間内で処理しなければなりません。しかし、処理するデータの量は処理するごとに違います。当然データの量が多くなれば処理する時間が長くなります。ではどうやって処理の時間を短縮することができるのでしょうか。ここでは処理の時間を短くする方法について考えていきましょう。
一昔前までは通常のパソコンのCPUはシングルコアで、サーバになるとデュアルコアといった具合でした。しかし、現在はディアルコアも普通になってきており、コア数が多いCPUも安価になってきております。
CPUのコア数が多いということは、同時に別々の処理が可能になります。いわゆる「並列処理」です。
この「並列処理」をうまく活用することで処理の高速化が図られます。
並列処理には「タスク並列処理」と「データ並列処理」の2つの方法があります。
タスク並列処理は依存しない処理を並列して行う処理です。いわゆるプログラムを並列で実行するというものです。この場合、並列処理を終了し統合を行う場合にどういったタイミングで統合を行うかが重要となります。双方の処理タイミングに大きな差がある場合、片方の処理が「待ち状態」になるといったこともあります。
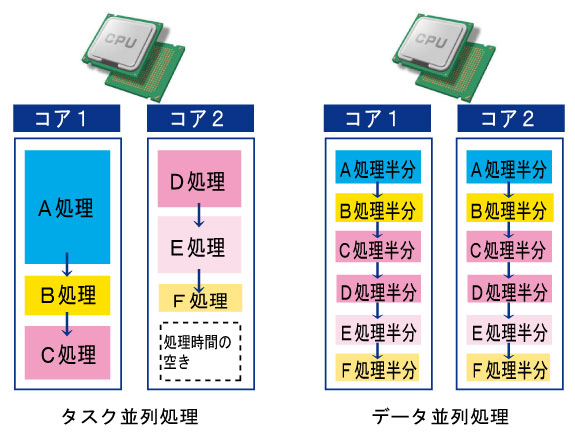 ▲タスク並列処理とデータ並列処理
▲タスク並列処理とデータ並列処理
データ並列処理は処理するデータを分割して同時に処理を行う方式です。どの区分でデータをまとめるかにもよりますが、この方式の場合、データを各区分に分けて管理している場合などでは大きな処理の短縮が図られます。データを区分する場合はパーティションごとなどに分け、あくまでもアプリケーションからみた場合は一つのデータテーブルのようにして、バッチ処理を行うときにパーティションごとに処理する方法があります。
3.バッチ処理でエラーが起きた場合の対処方法
エラーが起こった場合、エラーの情報が鍵となります。

バッチ処理の場合、エラーが起きた場合の対処方法も重要になってきます。バッチ処理の場合、更新している最中は人による監視はほとんど行っていません。しかし、エラーが起きた場合、その時点で処理をストップしてしまうと、後の処理に影響を及ぼします。そこでエラーが起きた場合に次の処理を行うか、もう一度処理を行うか、あるいは一旦処理を中止するのかという判断をプログラム自身で判断しなければなりません。また、どの箇所がエラーなのか後で普及できるようにエラーの情報を残さなければなりません。
まずは予想できるエラーの内容をすべて抽出し、それに基づいた判断をプログラムに組み込まなければなりませんが、エラーが起きた場合にスキップして処理を行う方法に次の2種類があります。
指定された処理をエラーのデータを除きもう一度最初から行う方法(リロード)とエラーのデータを飛ばして次のデータから処理を再開する方法(リラン)があります。
リロードの場合、エラーで終了した場合は一旦元のデータに戻してから再度処理を行います。この方法は特に売上金額の更新など数字が絡んだ場合に用いられる方法です。
売上金額などは日々変化しており、なおかつ正確さが求められます。途中でエラーなった場合、どこまで更新してどこから再開しなければいけないのか分からなくなる可能性があります。そのため、一旦データを前の状態に戻し、エラーの箇所が特定なった時点で再度バッチ処理を行う必要があります。
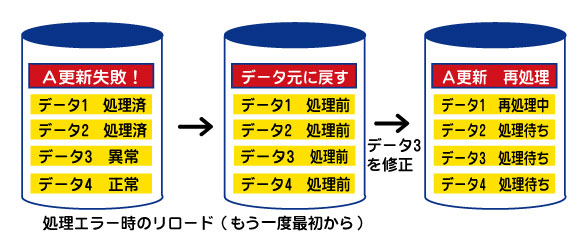 ▲バッチ処理でのエラー時のリロード
▲バッチ処理でのエラー時のリロード
リランの場合はマスター更新など新しいデータが目的の場合などに行われる処理です。この方法はそのレコードに対しての処理のため、エラーになったレコードを飛ばしても、他のレコードの情報には影響がありません。
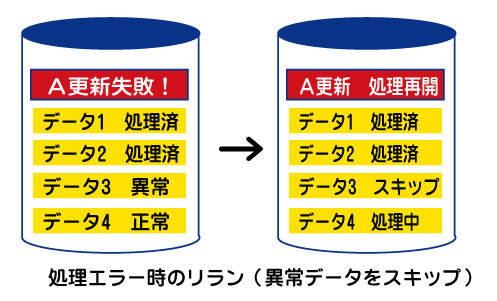 ▲バッチ処理でのエラー時のリラン
▲バッチ処理でのエラー時のリラン
このように使用用途によってエラーが起きた場合の対処方法が違ってきます。しかし、ここで重要なのはエラーが起きた場合の情報が必要となり、エラーが起きた場合は必ず「ログ」を保存しなければならないということです。ログの保存の場合、どの処理でどのデータがいつ、どんな状態でエラーがなったのかを詳しく記載しないと、エラーが起きた場合の対処が難しくなります。また、ログを保存すると同時にエラーになったデータの退避も考慮しなければなりません。ログは残っているけれども、元のデータが消えていたり、更新しようとしているデータがなかったりといった場合もあります。
 ▲更新時のログ採取が重要
▲更新時のログ採取が重要
通常ログの場合は処理の成功・失敗共に記されます。その場合、開始時刻・処理内容・終了時刻も記載し、処理が長くなっているかどうかの判断にもなります。また、一見処理が成功しているように見えても、処理の時間が非常に長い場合はエラーが起きているといった判断もできます。
ログを保存する場合、ログファイルの大きさにも考慮しなければなりません。最初からすべて毎日ログを保存しているといずれは大きなファイルになり、探すのも大変になります。通常はログファイル内でローテーションしており、新しいログは古いログに上書きする方式をとっています。その場合、どこまでの古いログが必要なのかを考慮してローテーションを行う必要があります。



